통계적 가설검정 이란 ?
통계적 가설검정이란 표본(샘플링 : sampling) 즉, 전체가 아닌 일부의 데이터를 가지고 전체 데이터 (모집단)의 값을 추측하는 것을 말한다.
여기에서는 알아야하는 개념이 있는데, 그것이 바로 귀무가설과 대립가설이다.
귀무가설은 null hypothesis 라고 하며, 기존의 상태를 말한다.
대립가설은 alternative hypothesis 라고 하며, 기존의 상태에 반하여 주장하려는 상태를 말한다.
예를 들어서 이런 상황을 가정해보자.
A학원에서 공부한 학생들이 있는데, 이 학생들이 학교에서만 공부한 학생들이 성적이 더 높은 것같아서 실제로 그런지 알아보고 싶다고 해보자.
여기에서 귀무가설은 변화가 없을 가정하는
귀무가설 : A학원생의 성적은 일반학생과 성적의 차이가 없다.
가 되고, 대립가설은 아래와 같다.
대립가설 : A학원생의 성적이 일반학생들 보다 높다.
그런데, 전체 학생들의 점수를 모두 체크한다면 가설검정같은것도 필요없이 평균점수를 비교하면 되겠지만, 전수 조사에는 많은 비용이 드는 경우가 많아서 일부의 표본으로 그 전체값을 예측하려는 것이다 보니, 100% 정확할 수가 없다.
그러다 보니 두 종류(타입)의 오류를 범할 가능성이 존재한다.
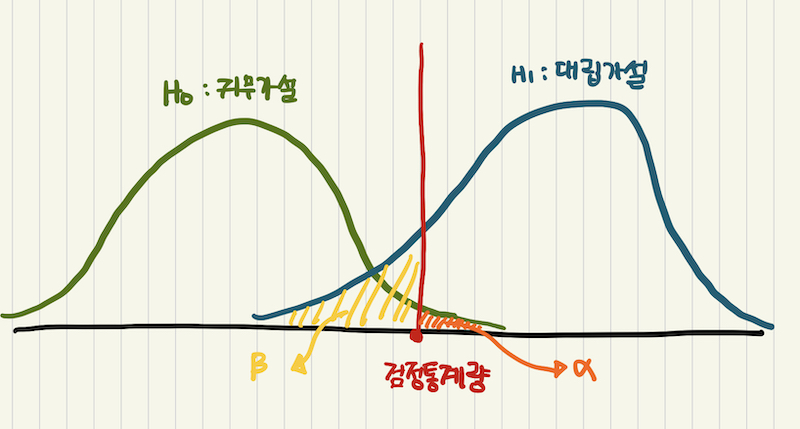
위 그림에서 초록색이 일반 학생의 성적이고, A학원생의 성적을 표본을 추출했을때, 실제로는 두 그룹이 차이가 없는데 표본이 잘 못 추출되어서 더 성적이 높게 나타날 수 있다.
이를 1종 오류라고 말한다.
다시 말하면, 귀무가설이 실제로 참이지만, 표본의 값이 귀무가설을 기각하는 오류를 말한다. (위 그림에서 오렌지색의 α(알파) 부분이다.)
반대로 A학원생의 성적이 실제로는 높은데, 표본이 균등학게 추출되지 않아서 차이가 없는 것으로 나타날 수 있다.
이를 2종 오류라고 한다.
다시 말하면, 대립가설이 실제로는 참이지만, 표본의 값이 귀무가설을 기각하지 못하는 오류를 말한다. (위 그림에서는 노란색의 베타 부분이다.)

그래서 통계학자들은 1종 오류가 일어날 확률의 최대 허용치를 정하게 되었다.
그 1종 오류의 최대 허용치를 유의수준이라고 한다.
보통 유의수준으로 5%를 많이 사용하는데, 유의 수준이 5%라는 말은 1종 오류가 일어날 가능성을 5% 이하로만 인정하고, 5%보다 크다면 귀무가설을 기각하지 않는다.
통계검정의 값(검정통계량)이 나올 확률은 유의확률(significant probablity) 또는 p값(p-value) 라고 한다.
그래서 기본적으로는 귀무가설이 맞다고 가정을 하면서, 검정통계량의 확률 P-value 가 0.05 보다 작다면 (즉, 유의수준 안으로 들어오면 ) 표본의 값이 이렇게 치우치게 나올 확률이 너무 적으니 (유의수준보다 적으니) 대립가설이 맞겠다는 합리적인 추론을 하는 것이다.
그리고 통계에서 말하는 검정력(statistical power)란 맞는 대립가설을 잘 선택할 확률
즉, 위 그림에서는
'분석 > AB 테스트' 카테고리의 다른 글
| 04. 실험 플랫폼과 문화 (1) | 2023.12.01 |
|---|---|
| 03. 트위먼의 법칙과 실험의 신뢰도 (0) | 2023.12.01 |
| 02. 실험의 실행과 분석 End - To - End 예제 (0) | 2023.12.01 |
| 01. 소개와 동기 (0) | 2023.12.01 |
| A/B 테스트의 과정 (Process) (9) | 2023.08.09 |



