머신러닝 모델은 문자 데이터를 인식하지 못합니다.
그렇기 때문에 문자로 구성된 데이터를 숫자형태로 바꿔줘야하는데 이를 인코딩이라고 합니다.
인코딩은 아래와 같이 두 종류가 있습니다.
1. Label Encoding (레이블 인코딩) : 원본 데이터의 값에 사전순으로 번호를 매깁니다.
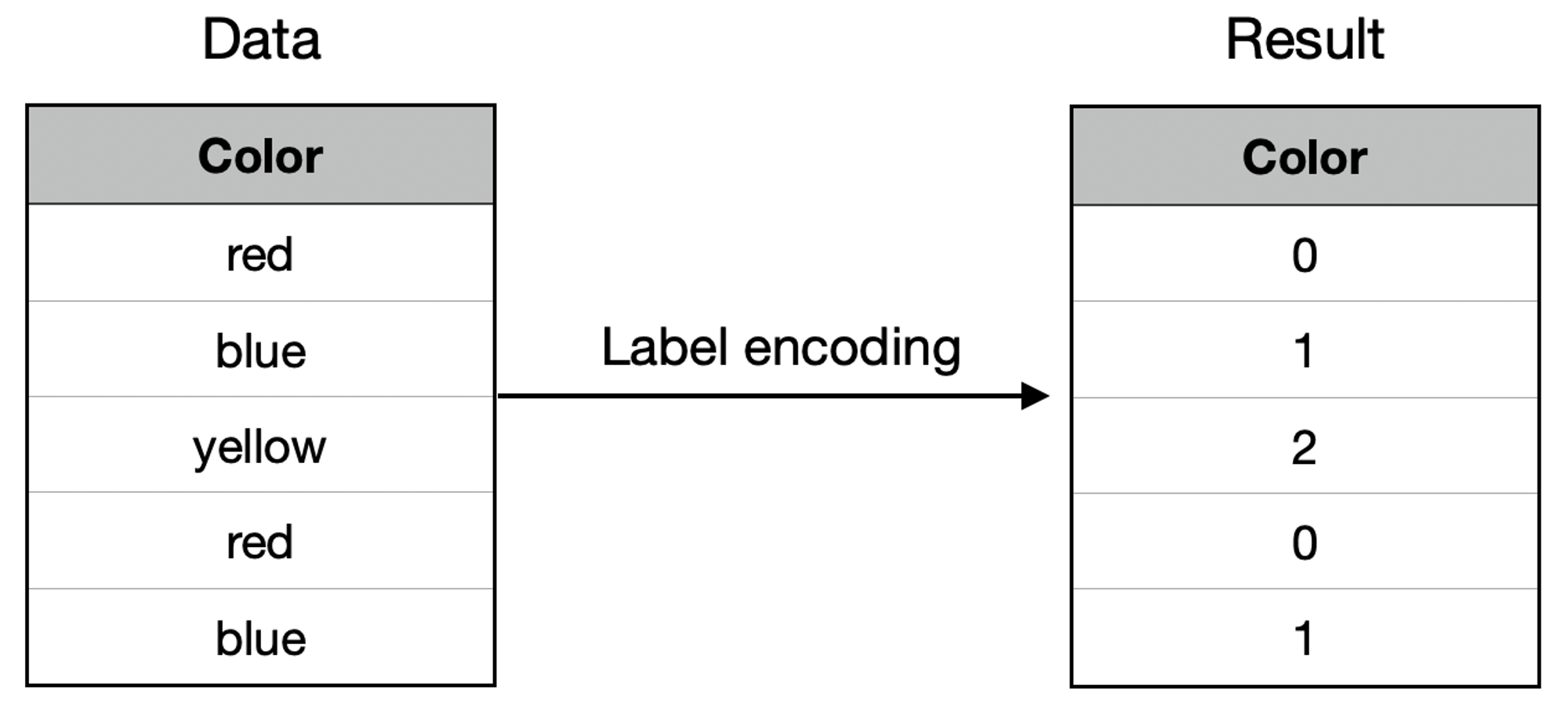
2. One-Hot Encoding (원-핫 인코딩) : 여러 값 중에 하나(one)만 활성화(hot)하는 방법입니다.
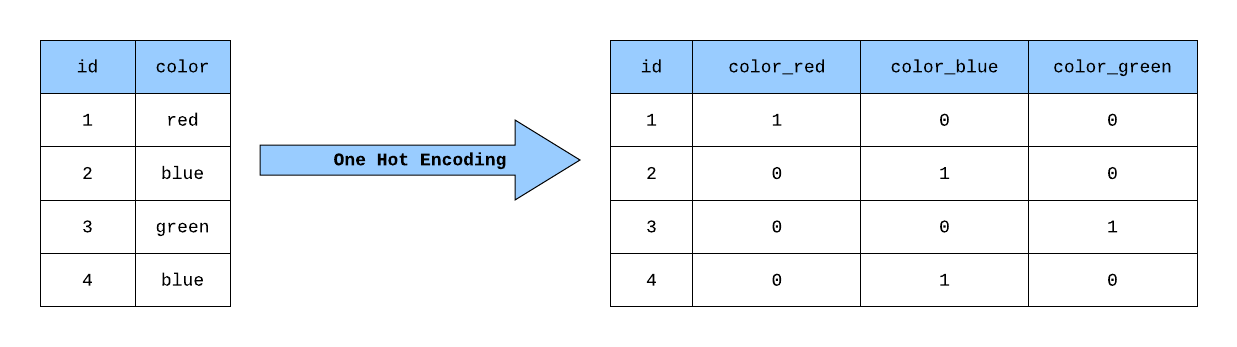
위 두 방식을 python 코드로 구현해보겠습니다.
1. Label Encoding
from sklearn.preprocessing import LabelEncoder
fruits = ['apple', 'orange', 'banana', 'pear', 'apple', 'banana', 'orange', 'apple', 'pear', 'banana']
label_encoder = LabelEncoder()
furits_encoded = label_encoder.fit_transform(fruits)
furits_encoded
2. One-Hot Encoding
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
fruits = ['apple', 'orange', 'banana', 'pear', 'apple', 'banana', 'orange', 'apple', 'pear', 'banana']
label_encoder = LabelEncoder()
onehot_encoder = OneHotEncoder()
fruits_label_encoded = label_encoder.fit_transform(fruits)
fruits_onehot_encoded = onehot_encoder.fit_transform(fruits_label_encoded.reshape(-1, 1))
print('원-핫 인코딩 결과 데이터 : \n', fruits_onehot_encoded.toarray())
[참고]
one-hot 인코딩은 아래와 같이 더 간단하게 구현할 수도 있습니다.
import pandas as pd
fruits = ['apple', 'orange', 'banana', 'pear', 'apple', 'banana', 'orange', 'apple', 'pear', 'banana']
pd.get_dummies(fruits)

'분석 > 데이터분석' 카테고리의 다른 글
| 그룹별로 랜덤 sampling 하기 (0) | 2024.08.27 |
|---|---|
| 피처 스케일링 (Feature Scaling) (0) | 2024.05.22 |
| 회귀모델의 성과 측정 (0) | 2024.05.22 |
| Recursive Query (재귀쿼리) (0) | 2024.03.12 |
| 분류모델의 성과 측정 (0) | 2024.02.23 |


